
Dispatch #2
"Inverse SEO", Google Devouring Media, and Berkeley Turkeys



We’re building The Dispatch, an AI project analyst for managers and execs, using our experience working with software teams of all sizes to help teams communicate better, spot risks early, and work more efficiently. We’ll post weekly about our progress, lessons learned, and related topics of interest e.g. AI, productivity, epistemology, etc.

After a brief on-site in Berkeley last week, we’re back with renewed vigor eyeing the summer ahead. Tacos were a must, as was a campus / forest walk. The occasion? Celebrating the roughly 3-month anniversary since making a full-time commitment to The Dispatch, and taking some time to review the course ahead.
Breathe in some of that sweet hills-of-Berkeley air and dive in with us.
Latest @ The Dispatch
New customers. Onboarding continues, the latest of which focuses on weekly analysis (e.g. code, Jira, Slack, Figma) for a long-lived and complex backend + its new client. Among areas to explore further is identifying bottlenecks in the product development process.
Inverse SEO? We’ve long run daily Dispatches against trending Github repos as it’s helpful to build up a back catalog and learn about interesting projects. Recently, the fine folks at Tracecat – which looks very useful, btw – found us researching their SEO and reached out to see if we could provide weekly reports for their open source project based on a report that we generated, mainly to update their community. A pleasantly unexpected turn, as we love OSS but have largely had our sights on how we can benefit orgs working predominately closed source. Watch this space for forthcoming webhooks, by request.
Product initiative alignment. Understanding how team effort maps to high level initiatives can be time-consuming and tedious to report on. We’ve long hypothesized that Dispatch could help to automate this, given reasonably simple inputs even without perfectly defined data in Jira, etc. We had our first test of this recently and the results are promising – more on this as it develops.
AI World
Much ink has been spilled skewering Google’s AI-assisted Search Results, which in my small sample size have been spot-on, but does raise ever-deeper concerns about the future of human-written media. PJ Vogt’s never-more-aptly-named podcast Search Engine entertainingly and helpfully analyzes this topic in the wake of Google’s announcement.
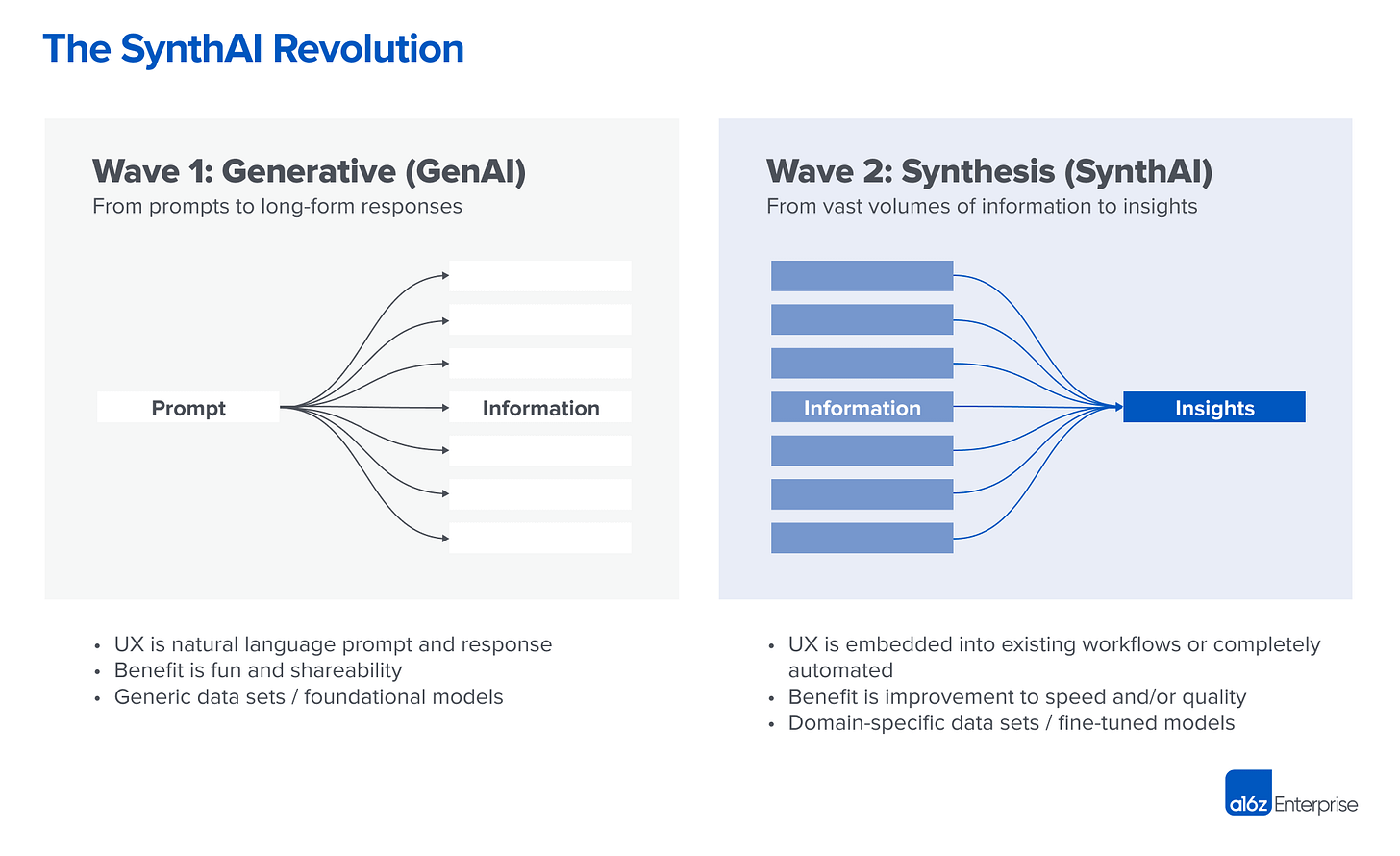
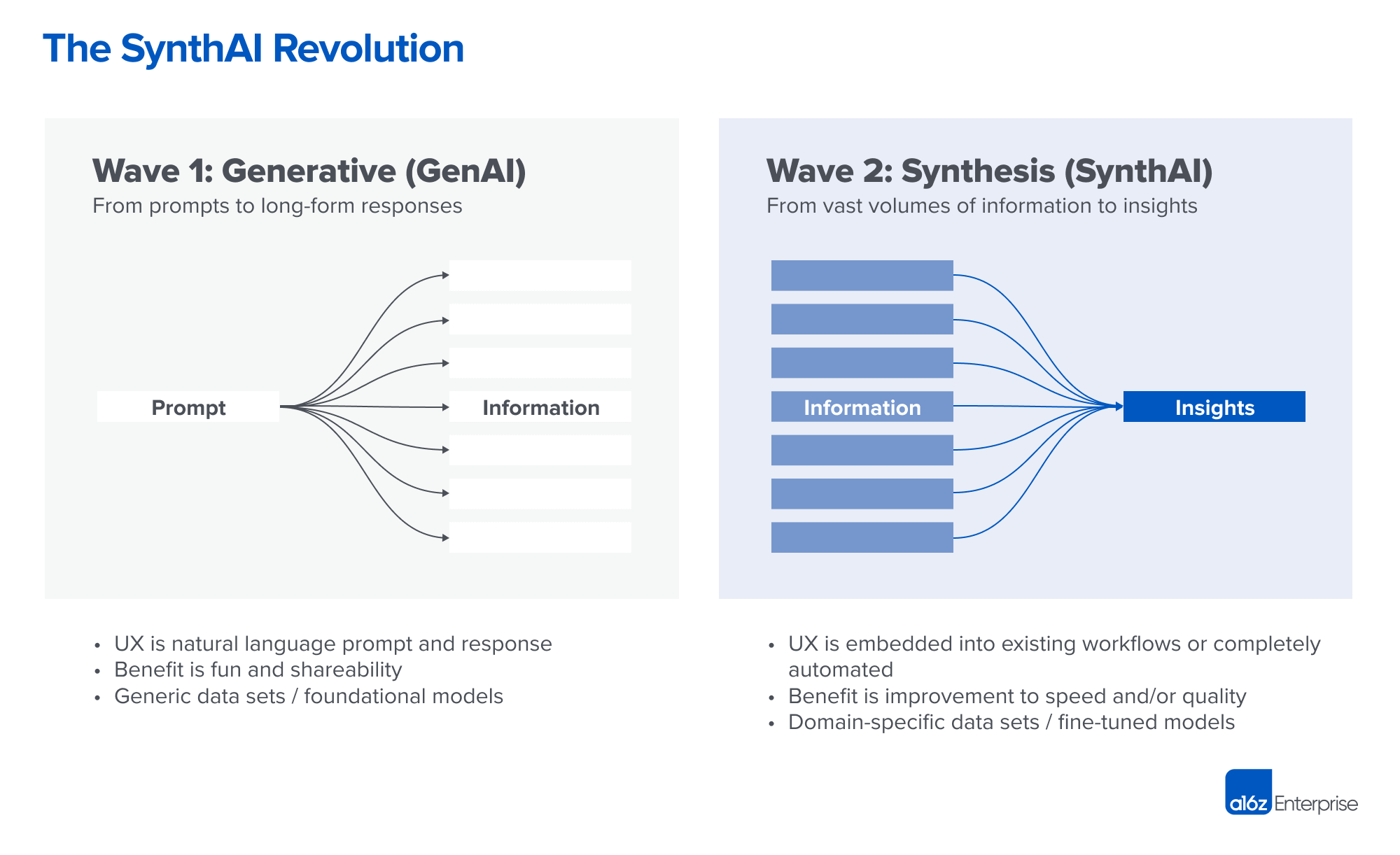
A16z posted an update yesterday on their prediction about “Wave 2” of B2B AI applications which focus on synthesizing information. It’s helpful to have better language around what we’re focusing on – in our case, automating insight generation based on inputs. The predictions seem at least plausible as well, especially with the improvements in multimodal interaction from OpenAI and Google. We’re stubbornly sticking with trad UX for now, but the possibilities opened up are intriguing.
Box CEO Aaron Levie tweeted (yes, tweeted) about RAG that resonated with us:
“The AI's answer is only as good as the underlying information that you serve it in the prompt. And because the user isn't the one giving it the data, but instead a computer, you're at the mercy of how good that computer is at finding the right information to give the AI to answer the question. Which means, of course, you're also at the mercy of how good, accurate, up-to-date, and authoritative your underlying information is that you're feeding the AI model in the prompt.”
As Jon noted: “This is why we are doing things the way we are doing things” We may do a deeper dive on what he meant by this, but suffice it to say we’re very picky about what information we share with LLMs and how we prepare it.
As sympathetic as we are to the pain point this addresses, this new YC-backed “thought leadership content creation as a service” startup misses the point if you believe – as we do – that writing is thinking. At least they’re not using AI to do this… yet.
Moment of Zen
Robb did not expect to see wild turkeys near the marina. That is all.

 | A guest post by
|
 | A guest post by
|